
There are already plenty of tools that can generate humanlike AI voice. Zonos-v0.1 is an open weight text to speech model that delivers expressive audio on par with top TTS providers. You will need up 5 to 30 seconds of speech to achieve high-fidelity voice cloning. You also get various voice options to choose from (American Male/Female, British Male/Female, Random).
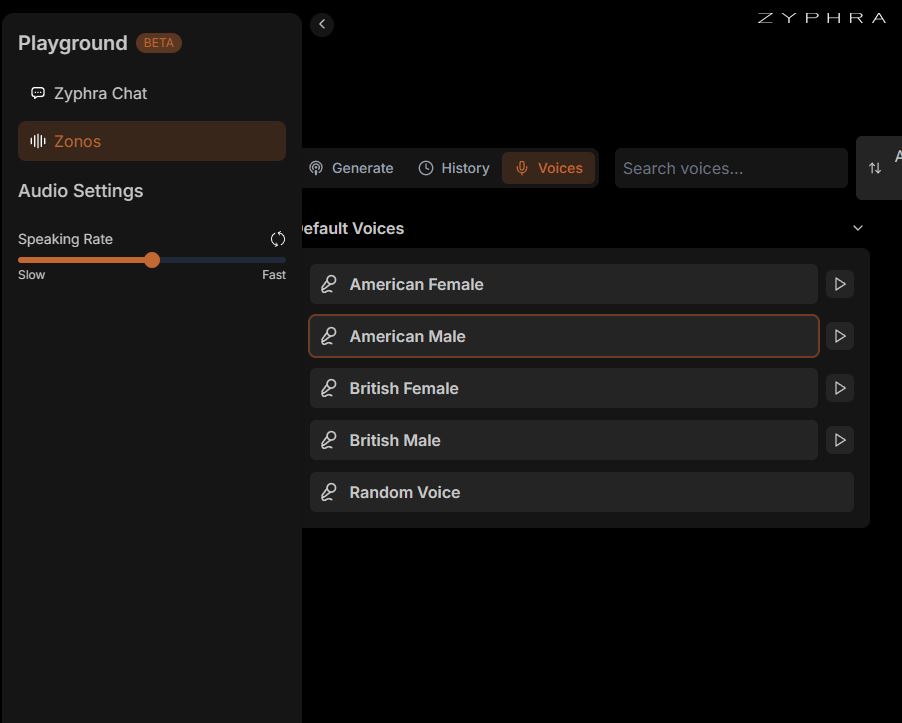
This model outputs speech natively at 44kHz. It was trained on 200k hours of English speech. With this tool, you get zero-shot text to speech. It supports English, Japanese, Chinese, French, and German.
Today, we’re excited to announce a beta release of Zonos, a highly expressive TTS model with high fidelity voice cloning.
We release both transformer and SSM-hybrid models under an Apache 2.0 license.
Zonos performs well vs leading TTS providers in quality and expressiveness. pic.twitter.com/jaliZNJecm
— Zyphra (@ZyphraAI) February 10, 2025
[HT]