
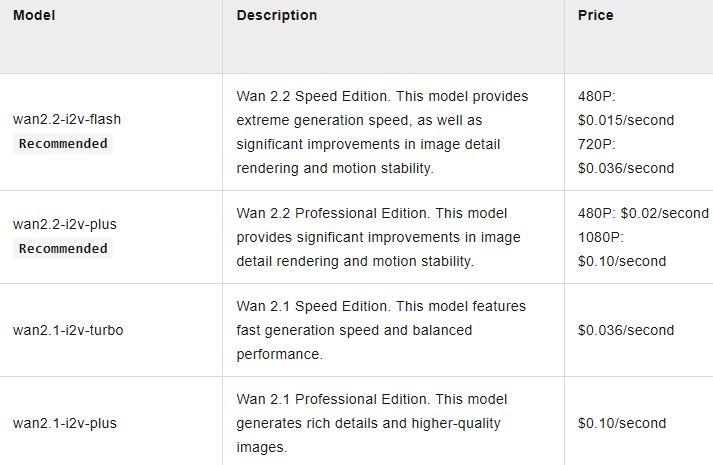
Wan2.2 is already very capable model. With Wan2.2-I2V-Flash, you can now generate videos faster and more cost effectively. Simply bring your images, and this model will maintain your style of images and generates natural motion. wan2.2-i2v-flash costs $0.036/second of 720o video. For wan2.2-i2v-plus, you can expect to spend $0.1 for every second of a 1080p video.
Today, we’re thrilled to announce the official launch of Wan2.2-I2V-Flash! It’s a major leap forward in generation speed and cost-effectiveness.
We’re dedicated to bringing you a faster, more professional, and more stable image-to-video experience.
Key highlights:
1️⃣12x Faster… pic.twitter.com/fmwB3vJD8F— Wan (@Alibaba_Wan) August 15, 2025
[HT]