
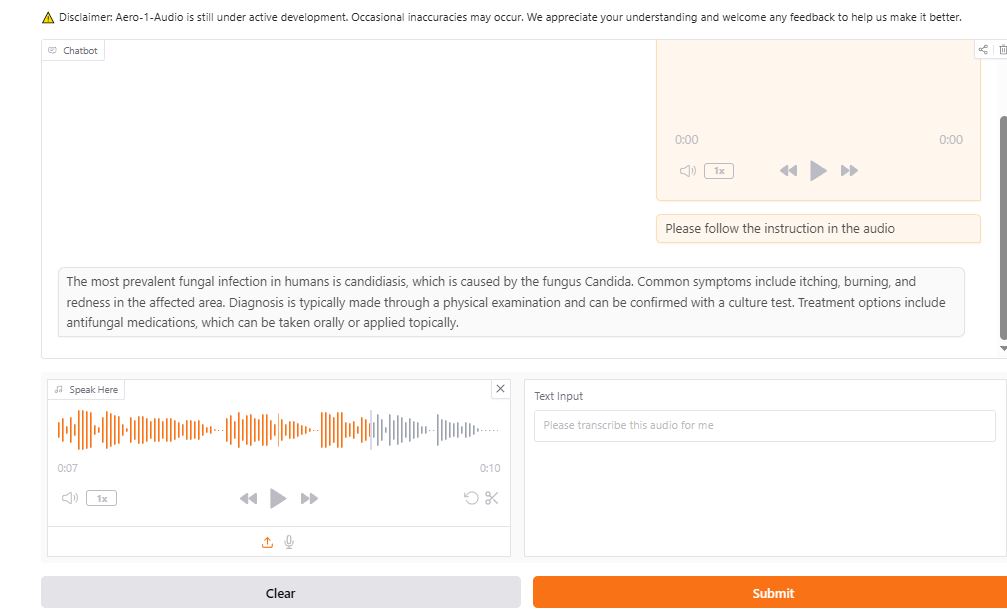
Here is an AI audio model that excels at automatic speech recognition, audio instruction following and scene audio analysis. It can handle long audio files up to 16 minutes without segmentation. It can not only transcribe your audio follows but also follow instructions in it. For example, you can ask a question in audio format and have the AI answer.
This model is built on Qwen-2.5-1.5B. It performs comparably to Whisper, Qwen-2-Audio, and Phi-4-Multimodal.
[HT]