

The good folks at DeepSeek are innovating all the time. With DeepSeek-V3.2-Exp, they have debuted DeepSeek Sparse Attention (DSA), which is an attention mechanism to make transformer models more efficient when handling long-context sequences. How is this different? In a normal transformer, every token looks at every other token. DS prunes away many of those and is more selective. This reduces the amount of computation and memory needed.
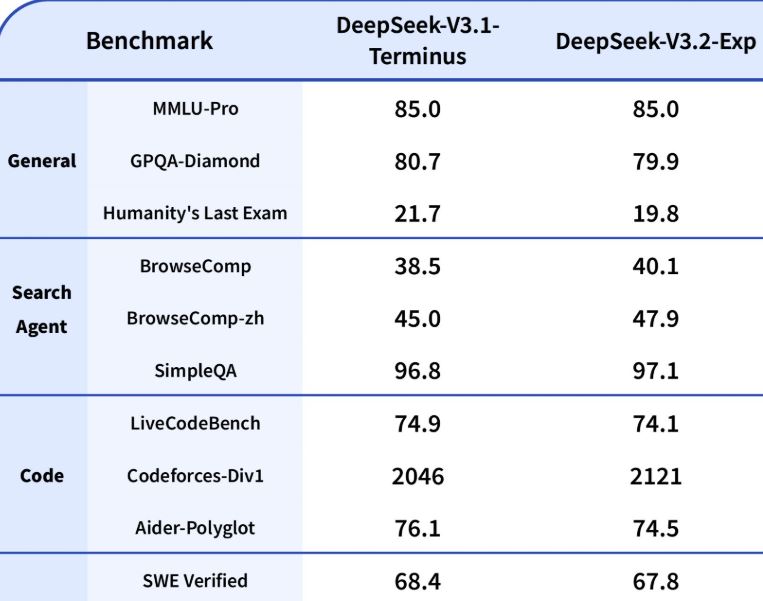
According to DeepSeek, this model doesn’t make a compromise on output quality while reducing compute cost and boosting long-context performance. Apparently, V3.2-Exp performs on par with V3.1-Terminus. More importantly, this is a pretty affordable model for API calls.
[HT]