
When it comes to text to speech, many of us are used to ElevenLabs and other popular AI audio services. Hume’s Octave is also worth a look. It is a LLM for text to speech, which means you can design any voice with a prompt. You can control emotion and delivery much better than some of the other models we have tested.
Today, we’re releasing Octave: the first LLM built for text-to-speech.
🎨Design any voice with a prompt
🎬 Give acting instructions to control emotion and delivery (sarcasm, whispering, etc.)
🛠️Produce long-form content on our Creator StudioUnlike traditional TTS that just… pic.twitter.com/Fag70tJrod
— Hume (@hume_ai) February 26, 2025
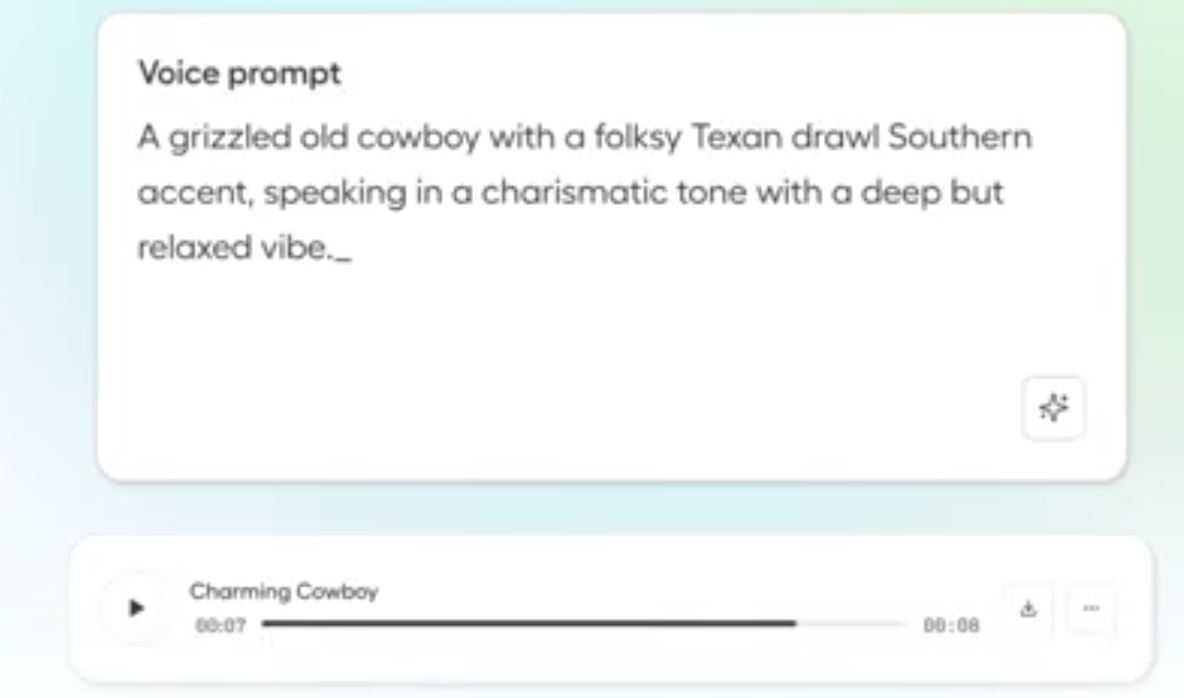
Octave can be used to create film noir detective and other human-like voices. It accepts natural language instructions to change delivery and speaking style.
🎬Acting Instructions
Octave is the first TTS system that can take natural language instructions to change emotional delivery and speaking style.
Give directions like “sound sarcastic” or “whisper fearfully.” For the first time, creators have total control. pic.twitter.com/gzRx16pR5z
— Hume (@hume_ai) February 26, 2025
[HT]