
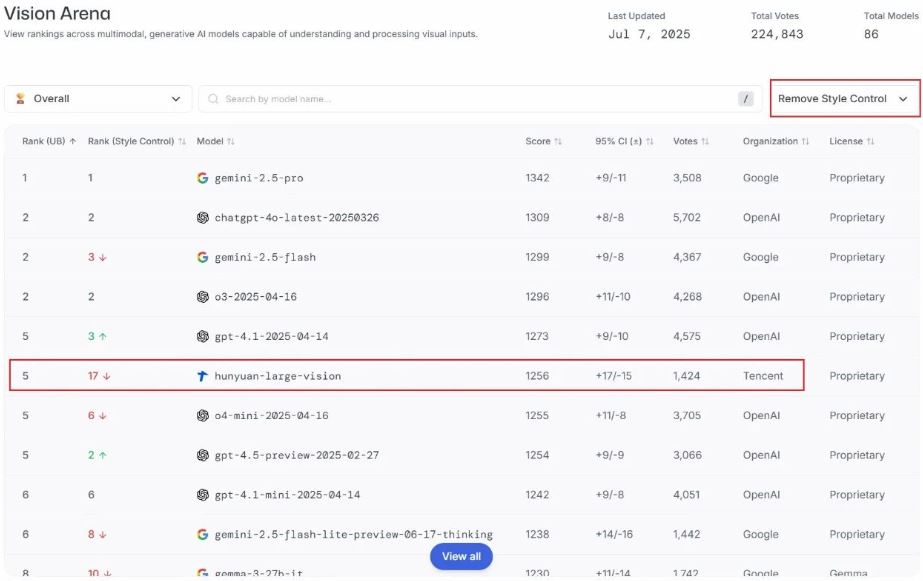
Here is another model that is designed for understanding images, videos, and 3D content. The Hunyuan-Large-Vision model has 389B parameters and 52B active parameters, so it delivers top performance in an efficient fashion. It scores high enough to be on par with GPT 4.5 and Claude 4 Sonnet. It is great at visual reasoning.

Hunyuan-TurboS-Vision and Hunyuan-T1-Vision are now enhanced with this. They will have APIs on Tencent Cloud for custom application development.
[HT]