
Those of you who have done AI video know about the challenges of adding audio and lip sync the characters. LatentSync from ByteDance is an open source frame work for end-to-end lip syncing. It uses Stable Diffusion to “model complex audio-visual correlations.”
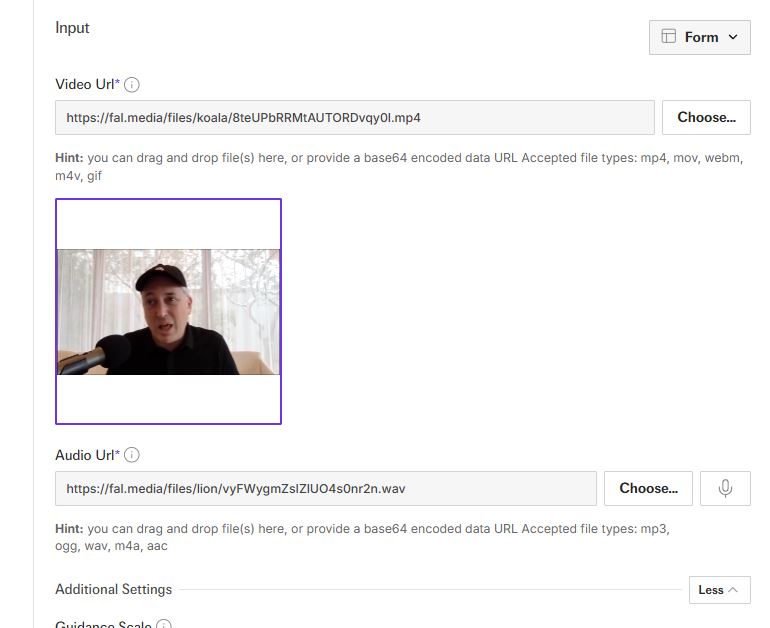
To get started, you just have to add your video and audio URLs and let the model do the rest. The model is currently available on Fal. You can change guidance scale for the model as well. As the researchers explain:
LatentSync uses the Whisper to convert melspectrogram into audio embeddings, which are then integrated into the U-Net via cross-attention layers.
[HT]