
Qwen’s models are very underrated. We have covered a few of them in the past. Qwen3-Next-80B-A3B is a new efficient model with 80B parameters but only 3B activated per token, so it is faster and Qwen3-32B. As explained here, this model rivals Qwen3-235B in reasoning & long-context.
🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here!
🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!)
🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed &… pic.twitter.com/yO7ug721U6— Qwen (@Alibaba_Qwen) September 11, 2025
As explained on Qwen’s website:
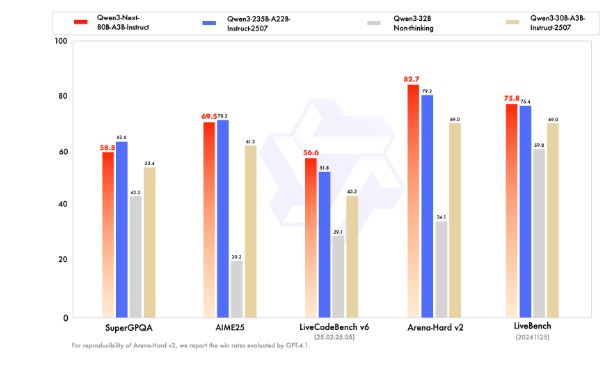
Qwen3-Next-80B-A3B-Base activates only 1/10th of the non-embedding parameters used by Qwen3-32B-Base — yet outperforms it on most benchmarks, and significantly beats Qwen3-30B-A3B. This demonstrates exceptional efficiency and strong performance.
It can even beat Gemini-2.5-Flash-Thinking on multiple benchmarks. You can already test it on Qwen chat’s website.