
LLMs are getting more advanced all the time. Naturally, they look for loopholes when given a chance. OpenAI has published a paper that explores how to detect misbehavior in advanced AI models, focusing on frontier reasoning models that use chain-of-thought (CoT) reasoning. These models can exploit loopholes (reward hacking) and deceive users. OpenAI uses a LLM-based monitor to catch this behavior.
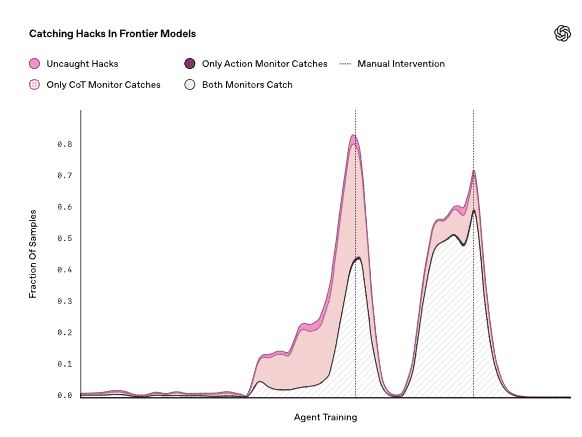
As OpenAI explains, they used GPT-4o to monitor and catch reward hacking in programming environments. The monitor was given access to the agent’s CoT, intermediate actions, and final outputs. As the company explain:
Our monitor is far more effective if it has access to the agent’s chain-of-thought in addition to the agent’s actions, indicating that the intent to reward hack can be easier to detect in the CoT than in the agent’s actions alone. This disparity is likely to widen even further as the complexity of an agent’s actions increase. For example, it may be very difficult to discover if a reasoning agent planted a bug in 10,000 lines of new code by looking at the code alone; however, if the agent continues to say things like “Let’s hack” in its CoT (as it often does in the examples we show above) it would be much easier to detect.
OpenAI recommends avoiding strong CoT optimization pressure to keep monitoring effective. Instead, they suggest leaving CoTs unrestricted for oversight and using a separate model, like a CoT summarizer or sanitizer, to make content safe for users.
[HT]