
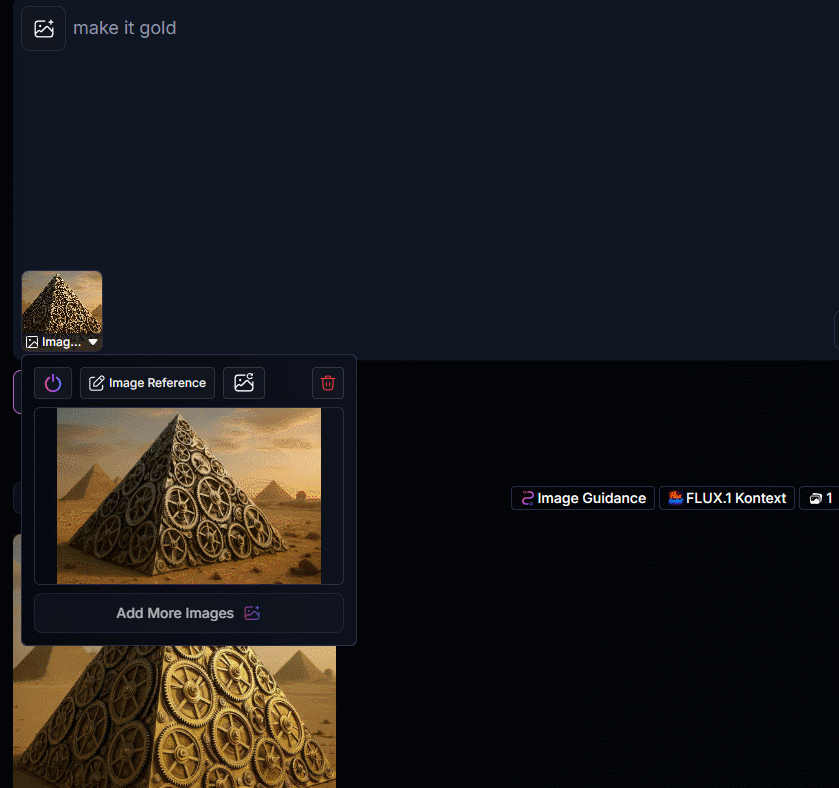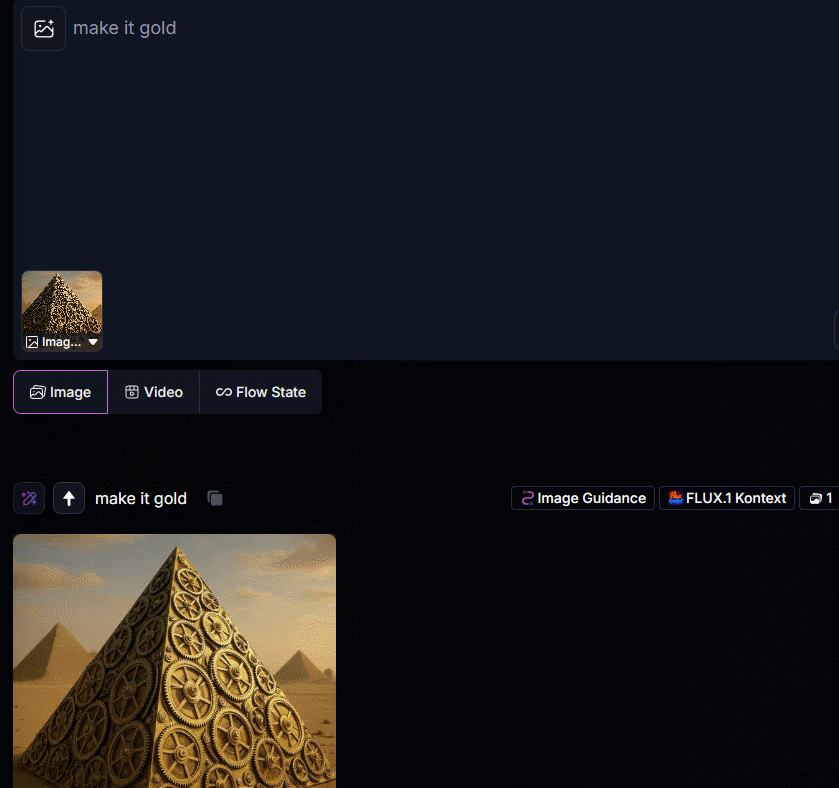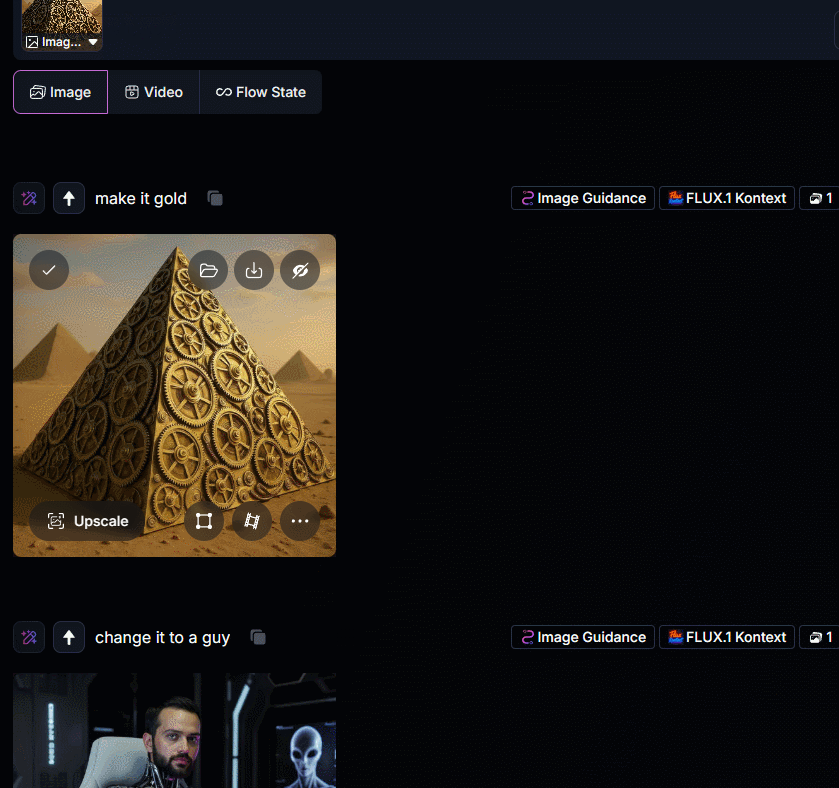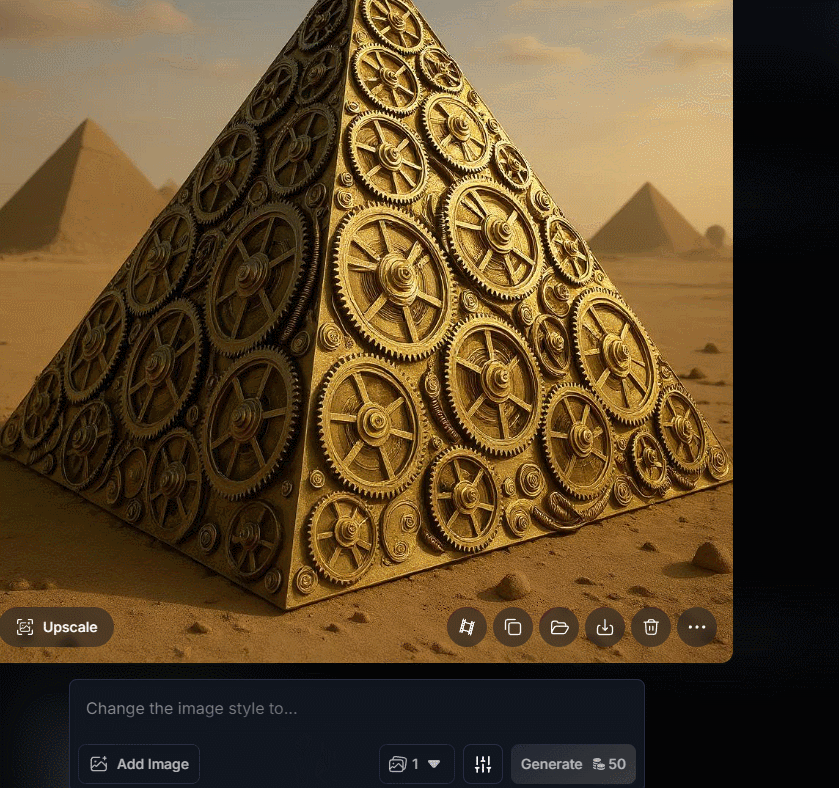
Leonardo is one of the most underrated AI image and video generators around. It is always adding new features. This time around, it has introduced Omni Editing, which is powered by FLUX.1 Kontext and GPT-Image-1. You can now edit any image right inside the viewer without switching tools.
There are differences between these models. GPT-Image-1 lets you add multiple images and bring them into your final generation. FLUX.1 Kontext was developed by Black Forest Labs. It is great for controlled edits that preserve key details. You can now change objects, lighting, and other aspects of your images. For GPT-Image-1, you can add up to 6 images as reference.
[HT]