
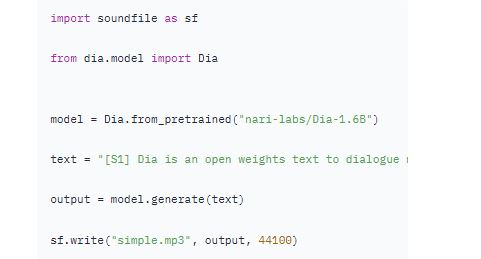
Sesame and ElevanLabs have some realistic sources. The Dia-1.6B model can give them a run for their money. It generates realistic dialog from a transcript. It comes with emotion and tone control, so it can produce laughter, coughing, and other nonverbal communications.
Here is how a prompt would look like when using this model:
[S1] Oh fire! Oh my goodness! What’s the procedure? What to we do people? The smoke could be coming through an air duct!
[S2] Oh my god! Okay.. it’s happening. Everybody stay calm!
[S1] What’s the procedure…
[S2] Everybody stay fucking calm!!!… Everybody fucking calm down!!!!! [S1] No! No! If you touch the handle, if its hot there might be a fire down the hallway!
You can test this tool on Hugging Face.